Bit-Slice Design: Controllers and ALUs
by Donnamaie E. White
Copyright © 1996, 2001, 2002 Donnamaie E. White
- Pre-Introduction
- Selection of the Implementation
- Microprogramming
- Advantages of LSI
- The 2900 Family
- Language Interrelationships
- Controller Design
- Constructing the CCU
- Sequential Execution
- Multiple Sequences
- Start Addresses
- Mapping PROM
- Unconditional Branch
- Conditional Branch
- Timing Considerations
- Pipelining
- Improved Architecture
3. Adding Programming
Support to the Controller
- Expanded Testing
- Subroutines
- Nested Subroutines
- Stack Size
- Loops
- Am29811
- Am2909/11
- CASE Statement (Am29803A)
- Microprogram Memory
- Status Polling
- Interrupt Servicing
- Implementation - Interrupt Request Signals
- Vector Mapping PROM
- Next Address Control
- Am2910
- Am2910 Instructions
- Control Lines
- Interrupt Handling
- Am2914
- Interconnection of the Am2914
6. The ALU and Basic Arithmetic
- Further Enhancements
- Instruction Fields
- Instruction Set Extensions
- Sample Operations
- Arithmetic -- General
- Multiplication with the Am2901
- Am2903 Multiply
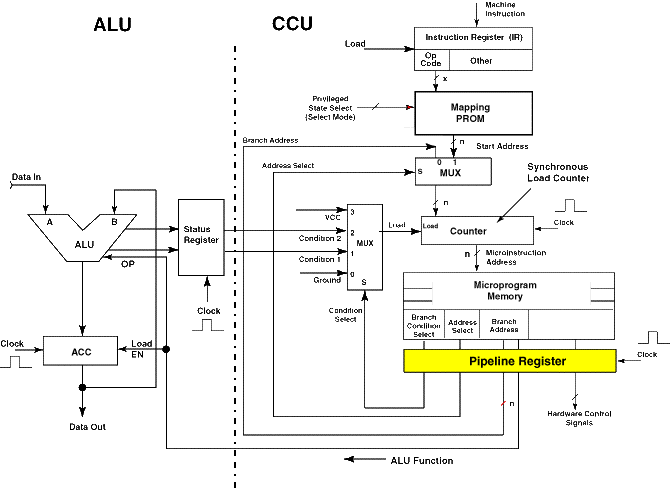
Simple Controller continuedLast Edit April 3, 1997; May 1, 1999; July 9, 2001 PipeliningTo improve speed, it is desireable to allow overlap of the ALU and memory fetch processes. This is possible by adding a register at the PROM output, called a pipeline register. The counter is acting as another pipeline register, holding the address thast the memory is fetching. The PROM pipeline will hold the current microinstruction under excution. This will allow the counter to move one count ahead and therefore will allow a memory fetch of the i + 1st microinstruction to be overlapped with the execution of the ith microinstruction. The configuration is shown in Figure 2-19. Figure 2-19 Simple System with A Pipleline Register Added (Reg., register)
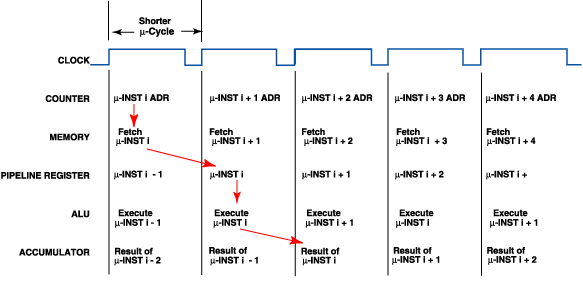
Figure 2-20 shows the timing diagram for sequential execution of this system. When the counter contains the address of the microinstruction i, the memory is fetching microinstruction i. The pipeline register contains microinstruction i - 1, which is under execution. If the microinstruction uses the ALU, the ALU is executing the commands of microinstruction i - 1 at this time. The accumulator contains the result of the execution of microinstruction i - 2; hence the reference of a two-level pipeline. Figure 2-20 Microcycle Timing for the Pipeline System, No Branch
On the rising edge of the next clock, the counter increments and the memory proceeds to fetch microinstruction i + 1. The pipeline loads with the outputs of the previous memory fetch, microinstruction i, and execution proceeds as before. The microcycle (no branch) is now: CP = Tcounter clock to output + TPROM read access or CP = Tpipeline clock to output + TALU execution whichever is greater. If we reasonably assume that the PROM read access time is not longer than the ALU execute time, then the second equation dominates. Pipeline BranchFigure 2-21 examines that happens in this case when a branch is executed. On the rising edge of the first clock, the address of microinstruction i is in the counter and memory is fetching the microinstruction at this address. Execution proceeds as before until the third clock signal. At this point the address of microinstruction i + 2 is in the counter and the memory is fetching microinstruction i + 2. On the next clock edge, microinstruction i + 2 cannot be loaded into the pipeline. A control must block one clock pulse to the pipeline register. The branch address is loaded into the counter, and the memory fetches this address. The piepline still contains microinstruction i + 1, the branch instruction which must not reexecute. Essentially, the execute phase is rendered idle during this microcycle. The n ext rising edge of the clock loads the branched-to address into the pipeline, and execution proceeds as before. The problems are obvious.
The process is called "flushing the pipeline" on execution of a branch instruction; since we have a two-level pipeline, it takes two microcycles to refill the pipe or to fully recover. This is not desireable if we branch often in a program because the time gained by overlapping memory fetch and ALU execution will be lost. We will ignore the extra hardware and implied programming constraints because we will now do it better. Figure 2-21 Microcycle Timing for the Pipeline System, Branch on Result
|